Who is BrandsEye and what is brandseyer2?
BrandsEye: opinion mining. Sentiment and topics.
What is sentiment? It’s always towards somethings. And people may be talking about particular topics.
Authenticating yourself
brandseyer2 provides API access to the BrandsEye API. In order to identify who you are, we provide our users with API keys on request. API keys are strings of randomly generated characters and numbers — they are difficult to guess, and very secure.
You can contact your account manager to get your API key. Once you have your API key, the first step to using brandseyer2 is to authenticate yourself, which you can do as follows:
library(brandseyer2)
authenticate(key = "<my api key>")This will let brandseyer2 know who you are. If you don’t want to type this in every time that you use brandseyer2, you can tell brandseyer2 to save your api key.
authenticate(key = "<my api key>", save = TRUE)Now, every time the library is loaded, brandseyer2 will immediately start using the saved API key.
Along with the authenticate function, you can also find out whose API key brandseyer2 is using:
whoami()
#> BrandsEye Credentials
#> name: Constance Neeser
#> email: connie@brandseye.com Now that you have authenticated yourself, you can begin to access your account information and mentions.
Overview
What is an account? What are mentions? What is the crowd, and sentiment and topics.
Some simple examples of pulling mentions for accounts, grouping, updating.
An account collects and structures the data that BrandsEye collects and processes for you. The smallest bit of data that we collect is a mention. A mention is a post on some social media network — for example, a tweet, or a facebook post, is a mention.
We collect mentions in brands. Brands define the point of interest of the mentions. Example brands may be the name of your company, a competitor, a well known individual, and so on. The sentiment of a mention is always measured towards the brand that the mention is collected in, and the brands also define what the topics that a mention may be about are.
Brands also organise the search phrases that we use to find mentions online for you.
Brands themselves are collected in accounts. Accounts also store extra information, such as what people get to access the data, how much Crowd verification the data receives, and so on.
Working with accounts
As someone who works with BrandsEye tools, you have a collection of accounts that you have access to. You can find this collection of accounts using account_list(), as follows:
This returns a tibble of accounts that are available to you. Importantly, it lets you find the account code (listed in the account, such as TEST01AA and TEST02AA) column that brandseyer2 uses to reference individual accounts.
Referencing an account
Nearly all the functions in brandseyer2 needs an account reference. You can refer to any account using it’s account code and the account() function. For example:
# Get a reference to the account TEST01AA
account("TEST01AA")
#> BrandsEye Account
#> Name: Test 1
#> Code: TEST01AA
#> Client: MKT001Many operations that you may want to perform will begin with finding an account reference, and then passing this on to other brandseyer2 functions using the pipe operator, %>%.
Here are some examples to find the name, code, and account manager of your account:
# Your account's name
account("TEST01AA") %>%
account_name()
#> [1] "Test 1"
# Your account code
account("TEST01AA") %>%
account_code()
#> [1] "TEST01AA"
# Your account manager.
account("TEST01AA") %>%
account_manager()
#> BrandsEye Client Service
#> name: Your Manager
#> email: noreply@brandseye.comBrands
Accounts are made up of brands. It is brands themselves that store individual mentions (such as tweets, facebook posts, and so on).
A brand is usually something that you would like to track on social media, and measure sentiment towards. All sentiment on a mention is always towards the brand that the mention belongs to.
You can find out what brands are in your account using the brands() function. Let’s have a look at what brands are in TEST01AA:
account("TEST01AA") %>%
brands()
#> # A tibble: 5 x 5
#> id name parent deleted archived
#> <int> <chr> <int> <lgl> <dbl>
#> 1 1 Your Brand Here NA FALSE NA
#> 2 2 Sibling Brand NA FALSE NA
#> 3 5 So deleted NA TRUE NA
#> 4 6 Brand of Christmas Past NA FALSE 1516710018.
#> 5 3 Niece Brand 2 FALSE NAThese tibbles can become a bit tight to display all of the data that you may want to see. If you are using RStudio, you can always pipe the results in to View(). Otherwise, you can subselect for the data you want using standard dplyr1 functions.
# Find brand IDs and names
library(dplyr)
account("TEST01AA") %>%
brands() %>%
select(id, name, parent)
#> # A tibble: 5 x 3
#> id name parent
#> <int> <chr> <int>
#> 1 1 Your Brand Here NA
#> 2 2 Sibling Brand NA
#> 3 5 So deleted NA
#> 4 6 Brand of Christmas Past NA
#> 5 3 Niece Brand 2There, that’s better. Now you can see that your TEST01AA account is made out of three brands. We’ve also selected another column called parent. We’ve done this to show the hierarchical nature of brands: some brands are children of other brands. Setting up an account in this way can help you to organise the mentions that are collected in a brand around more specific themes.
You can also discover this information for all the accounts that you have access to.
# Example hereNotice that one of our accounts have old brands that are no longer being used, and have been deleted. Also, we often want to find the top level brands that make up the main collections of mentions in an account. These “top level” brands are called root brands. We have a convenient function that finds the root brands currently in use in your account:
account("TEST01AA") %>%
root_brands()
#> # A tibble: 2 x 4
#> id name deleted archived
#> <int> <chr> <lgl> <dbl>
#> 1 1 Your Brand Here FALSE NA
#> 2 2 Sibling Brand FALSE NAWorking with mentions
Mentions can be read using the mentions() function:
Counting mentions
Mentions can be counted. The simplest way of doing this is with the count_mentions() function, and using a query language designed to do this.
Here is a simple query to count all mentions published the last week:
account("QUIR01BA") %>%
filter_mentions("published inthelast week") %>%
count_mentions()
#> # A tibble: 1 x 1
#> mentionCount
#> <int>
#> 1 8907More interestingly, we can count just the relevant mentions from the last week:
account("QUIR01BA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
count_mentions()
#> # A tibble: 1 x 1
#> mentionCount
#> <int>
#> 1 7918If you would like to know more about filtering in particular, see our Filtering vignette.
Now, counting mentions becomes interesting when we begin to do things such as grouping mentions. For example, we can group mentions by the published date.
account("QUIR01BA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
group_mentions_by(published) %>%
count_mentions()
#> # A tibble: 8 x 2
#> published mentionCount
#> <dttm> <int>
#> 1 2018-07-26 00:00:00 1410
#> 2 2018-07-27 00:00:00 1067
#> 3 2018-07-28 00:00:00 528
#> 4 2018-07-29 00:00:00 655
#> 5 2018-07-30 00:00:00 1389
#> 6 2018-07-31 00:00:00 1214
#> 7 2018-08-01 00:00:00 1124
#> 8 2018-08-02 00:00:00 532This is something that you could potentially chart, using a library such as ggplot2.
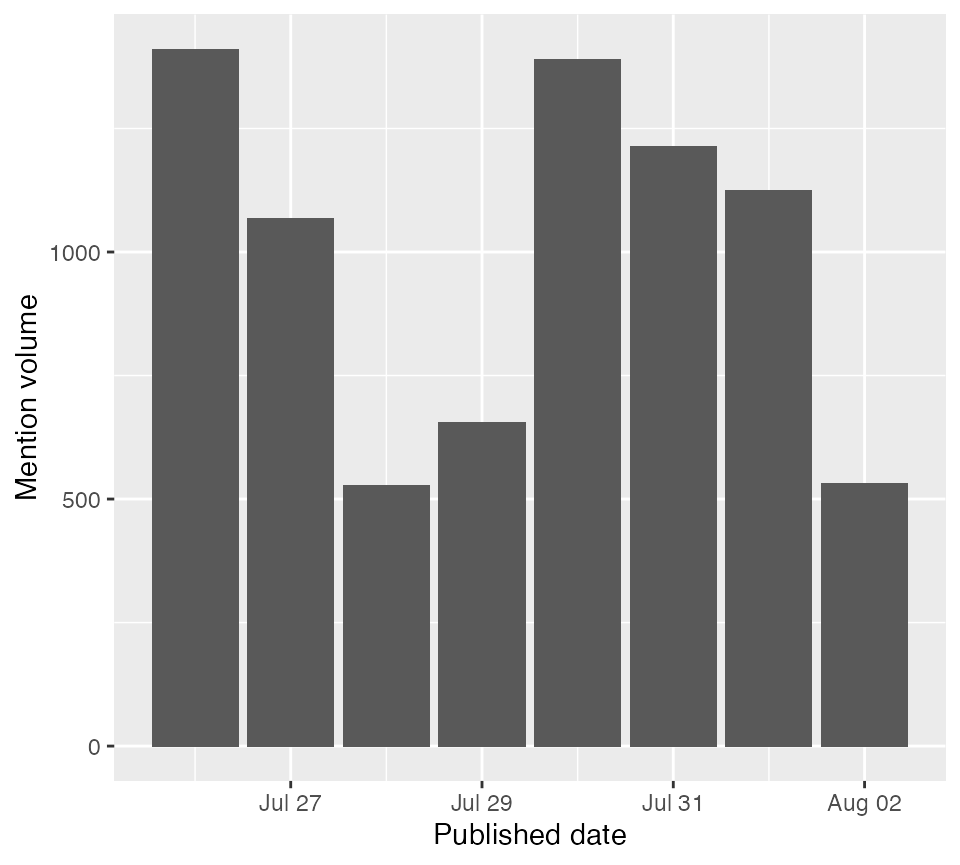
A plot of data pulled from the api
One thing to take note of is that at no point have we specified what brands we want to use in the filter. This happens automatically: the query language selects all the root brands. You can easily examine this by leaving out the final step in the pipe chain above, like so:
account("QUIR01BA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
group_mentions_by(published)
#> BrandsEye Query
#> accounts: QUIR01BA
#> brands: 35 brands selected
#> timezones: Africa/Johannesburg
#> filter: published inthelast week and relevancy isnt irrelevant
#> grouping: publishedIf you would like to see the filter being produced, you can do so using the to_count_filter() method. Let’s do this using an account with fewer root brands:
# Let's see what the query looks like
account("TEST01AA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
group_mentions_by(published)
#> BrandsEye Query
#> accounts: TEST01AA
#> brands: TEST01AA:1[Your Brand Here], TEST01AA:2[Sibling Brand]
#> timezones: Africa/Johannesburg
#> filter: published inthelast week and relevancy isnt irrelevant
#> grouping: published
# And this is the filter
account("TEST01AA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
group_mentions_by(published) %>%
to_count_filter("TEST01AA")
#> (published inthelast week and relevancy isnt irrelevant) and (brand isorchildof 1 or brand isorchildof 2)Notice that the group by doesn’t occur in the filter: this is additional data sent to the API when we request the data. This full filter is, however, sent to the API. It’s also an appropriate filter for use in Analyse or anywhere else that a filter is accepted.
A useful thing that the filter allows us to do is to count data across multiple accounts at a time. For example, you across two specific brands:
account("QUIR01BA", "BEUB03AA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
count_mentions()
#> # A tibble: 2 x 2
#> account mentionCount
#> <chr> <int>
#> 1 QUIR01BA 7951
#> 2 BEUB03AA 8466Again, you can group by any grouping field that you would want.
You can also count across all accounts that are available to you:
account_list() %>%
account() %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
count_mentions()
#> # A tibble: 4 x 2
#> account mentionCount
#> <chr> <int>
#> 1 QUIR01BA 7951
#> 2 BEUB03AA 8466
#> 3 TEST01AA 1234
#> 4 TEST02AA 1234A very useful thing that the query language provides us, is the ability to compare sub-groups of mentions using sub-filters. For example, if we want to find mentions inside and outside of Africa, we could so as follows:
account("QUIR01BA", "BEUB03AA") %>%
filter_mentions("published inthelast week and relevancy isnt irrelevant") %>%
compare_mentions(africa = "location is 'africa'", elsewhere = "location isnt 'africa'") %>%
count_mentions()
#> # A tibble: 4 x 3
#> account comparison mentionCount
#> <chr> <chr> <int>
#> 1 QUIR01BA africa 184
#> 2 QUIR01BA elsewhere 7139
#> 3 BEUB03AA africa 7850
#> 4 BEUB03AA elsewhere 295We have provided two seperate sub-filters, one labeled ‘africa’, one labeled ‘elsewhere’. Notice that these labels have now appeared in the result table, once for each account that we are querying.
What to read next
If you would like a more in-depth understanding of filtering, see our filtering vignette. Our Cookbook contains a lot of small scripts to perform specific tasks that you may find useful.